
AI Tech
Feb 17, 2026
A deep dive into building a white-label SaaS health platform with AI-powered lab analysis, tiered model routing, and per-clinic customization — from architecture decisions to production deployment.



Discover how DeepAgent Desktop outperforms GPT-5 Codex with top coding agent benchmarks, unique features, affordable pricing, and real-world demos.

SEO Content Writer








DeepAgent Desktop beats heavyweights like GPT-5 Codex and Claude Code on two hard, real-world tests: TerminalBench and SWE-bench Verified. It scored 48.75% on TerminalBench and 74% on SWE-bench Verified—numbers that reflect end-to-end engineering, not just code completion.
These benchmarks test terminal workflows, repo edits, and passing tests. That is why they matter for teams shipping real software.
SWE-bench Verified is widely seen as the gold standard because it checks if an agent can fix real GitHub issues end-to-end—edit, test, and submit. Early GPT-4 runs scored ~20–27%, while Claude 3.5 Sonnet hit ~44–47%. DeepAgent's 74% is a major leap.
TerminalBench, launched in 2024, measures command-line skill: navigation, compilation, debugging, and multi-step workflows. Top open-source agents hovered in the 30–40% range. DeepAgent's 48.75% leads.
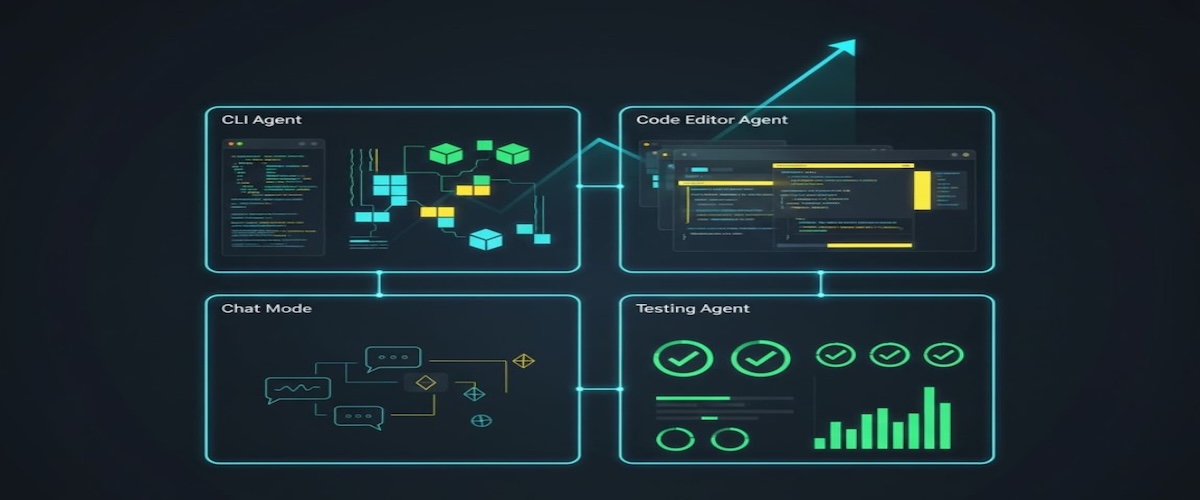
DeepAgent Desktop combines three modes—CLI Agent, Code Editor Agent, and Chat Mode—and adds an automated Testing Agent. This mix enables scaffold → edit → test → iterate inside one surface.
Work from the terminal. Create projects, wire routes, and run tests with short prompts. Demos include a retro Snake game and a LinkedIn-style app named ConnectHub. Quick start:
npx -y deepagent-cli
Behaves like an IDE powered by an agent. It reads a resume image (OCR), extracts data, and builds a polished site. It also ships interactive learning guides. The Testing Agent validates code automatically.
Switch models per task without leaving the app. Use Claude for reasoning, GPT-5 for structured edits, or Gemini for ideation.
These demos reflect repo-level work where many models still struggle. Benchmarks like SWE-bench and write-ups on its "Pro" variants raise the bar.
The basic tier is $10/month, undercutting or matching popular assistants. Desktop integration and the Testing Agent can replace multiple paid add-ons.
Weekly $2,500 build contests help the community share working examples—an engine for rapid learning and visibility.
An all-in-one suite beats tool sprawl: CLI + Editor + Chat + Testing in one place. Less context switching, more flow. Strong scores on TerminalBench and SWE-bench support this approach.
Multi-model Chat Mode reduces vendor lock-in: swap between GPT-5, Claude, and Gemini as needed.
Open your terminal and run:
npx -y deepagent-cli
Use it to scaffold a small app, wire tests, and ship your first patch.
Aim the agent at labeled queues such as "good first issue" or "chore," mirroring SWE-bench-style tasks for throughput.
Run guided fixes with tests and store a shared set of "prompts that work" for your codebase.
DeepAgent Desktop turns prompts into working patches. The bundle of CLI, Editor, Chat, and Testing Agents trims friction from idea to PR. High marks on SWE-bench Verified and TerminalBench support the claim with hard data. If you want less tool sprawl and faster, test-backed changes, this desktop suite is ready.
Start small: npx -y deepagent-cli, one scoped task, tight loops. Measure test pass rates and time to first patch. Many teams will find that DeepAgent Desktop earns a seat in the daily toolchain.
It's an all-in-one desktop suite: terminal agent, editor agent, multi-model Chat Mode, and a Testing Agent. It focuses on repo-level work, not just autocompletion.
No. It runs and validates tests to close the loop. You should still write clear, meaningful assertions.
Yes. Run npx -y deepagent-cli to start the CLI. Move to the editor for multi-file changes and automated validation.
Yes. Chat Mode lets you pick GPT-5, Claude, or Gemini per prompt, reducing lock-in.
Independent coding agent benchmarks like SWE-bench and TerminalBench report top scores that map to repo-level work.
Yes. Demos show scaffolds, data layers, and polished UIs built end-to-end.
The $10/month tier is budget-friendly. Run a 7-day pilot and track time to first patch, diff quality, and test pass rate.
Watch SWE-bench, TerminalBench, and independent comparisons for the latest updates.

A deep dive into building a white-label SaaS health platform with AI-powered lab analysis, tiered model routing, and per-clinic customization — from architecture decisions to production deployment.

Learn how Agentic AI in healthcare transforms care delivery with AI agents, automation, decision support, patient engagement, risks, compliance, and adoption strategy.

At NexGen, we specialize in AI infrastructure, from LLM deployment to hardware optimization. Our expert team helps businesses integrate cutting-edge GPU clusters, inference servers, and AI models to maximize performance and efficiency. Whether on-premise or in the cloud, we provide tailored AI solutions that scale with your business.
info@nexgen-compute.comCopyright © NexGen Compute | 2025

