









AI Tech
Feb 17, 2026
A deep dive into building a white-label SaaS health platform with AI-powered lab analysis, tiered model routing, and per-clinic customization — from architecture decisions to production deployment.



Grok 4 represents xAI’s biggest step yet toward building a model that doesn’t just generate plausible text, but actually reasons through problems.Launched on July 10, 2025, it integrates live browsing, a code interpreter, long-context support, and an optional multi-agent mode (Heavy) that lets multiple instances collaborate on hard questions before returning a consensus.
For researchers, engineers, and teams working on high-stakes tasks, that combination means:
The Grok family has evolved through compute scaling and, with Grok 4, a major paradigm shift in post-training:
At the core of this new strategy is Reinforcement Learning with Verifiable Rewards (RLVW). Instead of training only on text prediction, Grok 4 is fine-tuned intensively on problems with clear, checkable answers (like math and logic). Every time the model reaches the correct answer, it receives a reward. By running this loop at massive scale, xAI encourages Grok 4 to engage in genuine “thinking-like” behavior, leading to dramatic gains in reasoning benchmarks.
Think of Heavy as your “high-precision mode”—great for critical queries, less ideal for day-to-day tasks.
In the no-tools setting, Grok 4 scores 26.9% on HLE—ahead of other standard models. With tools enabled it jumps to 41.0%, and in the multi-agent ‘Heavy’ configuration it reaches the incredibly 50.7%.
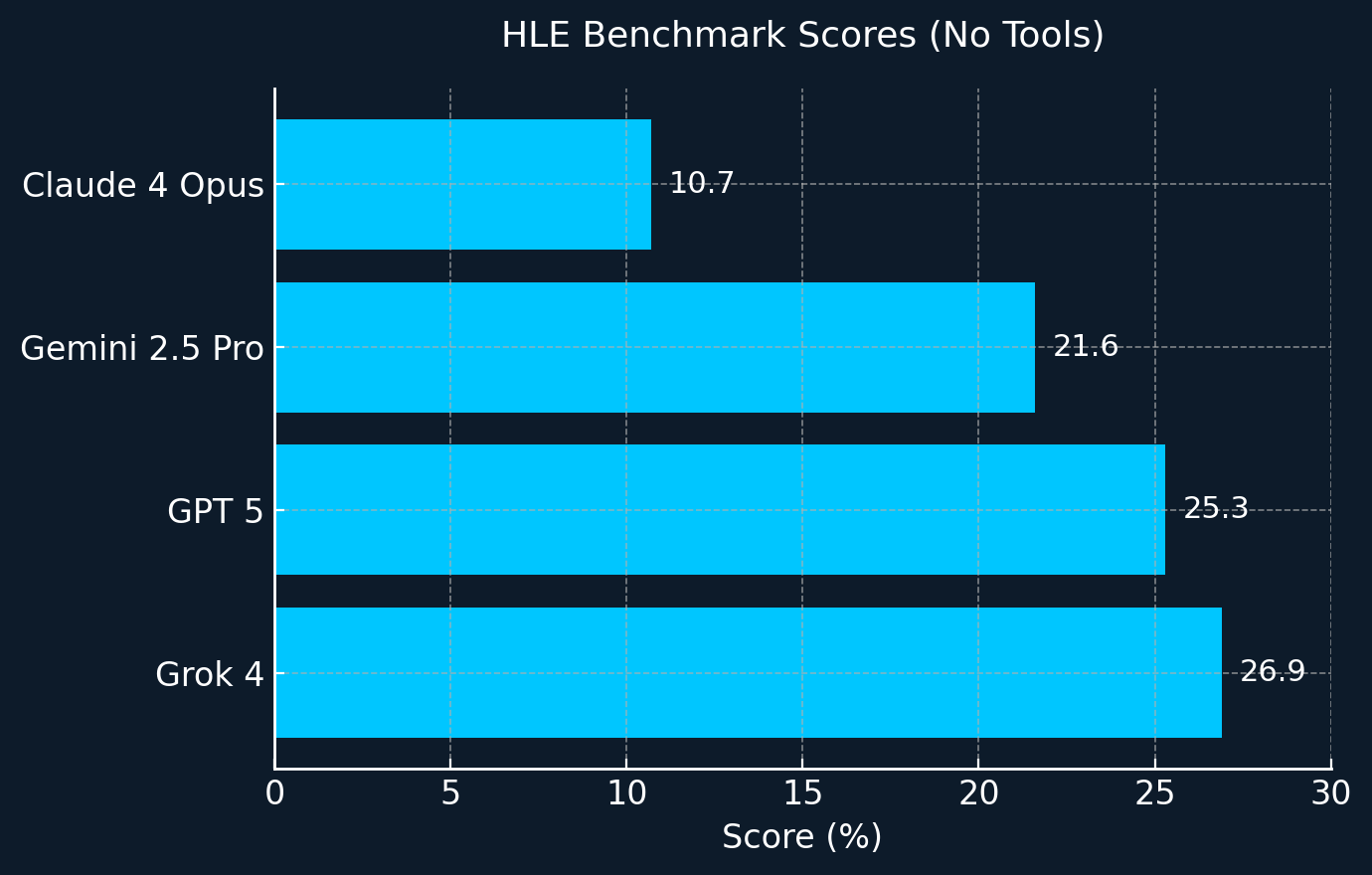
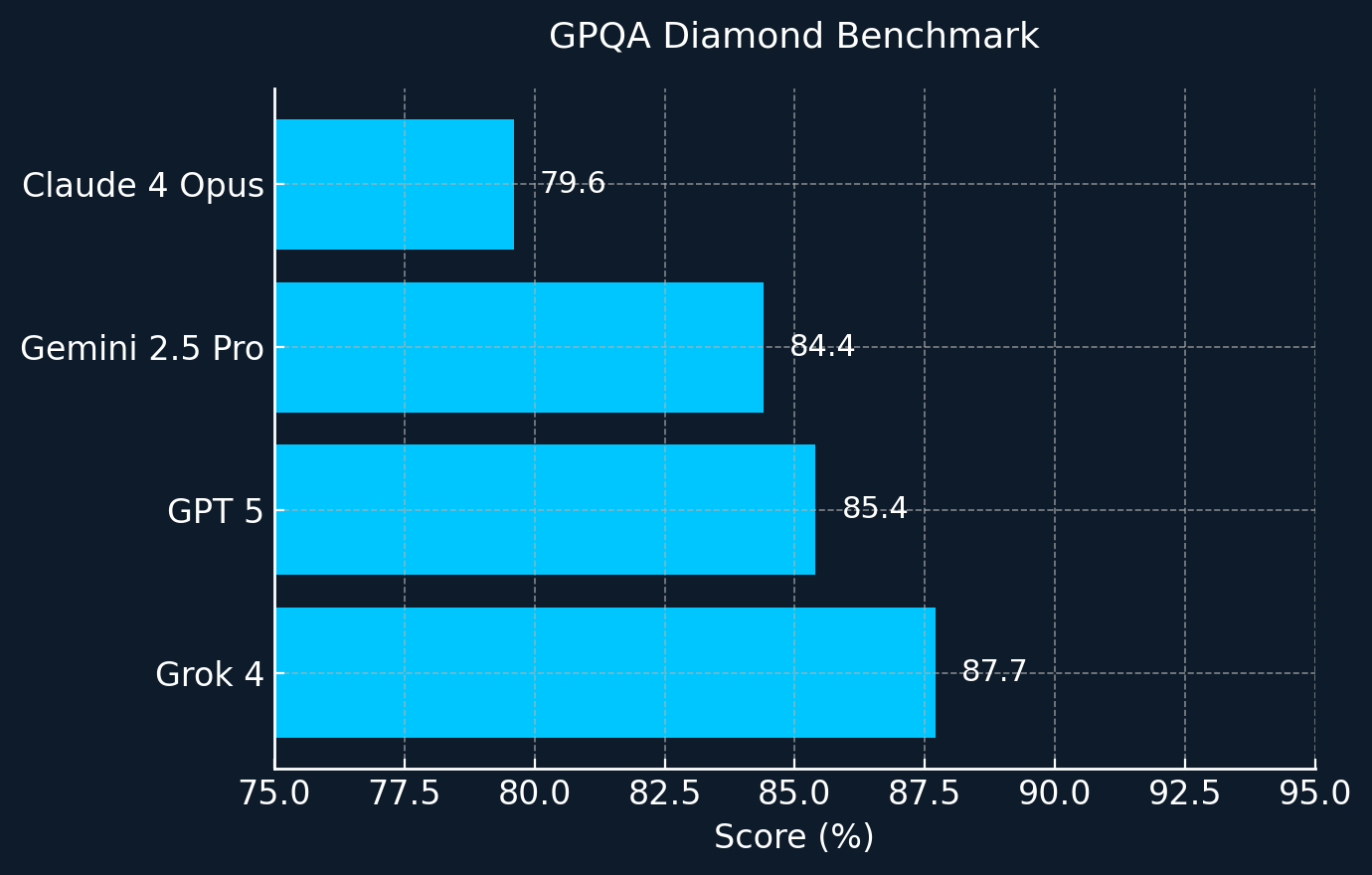
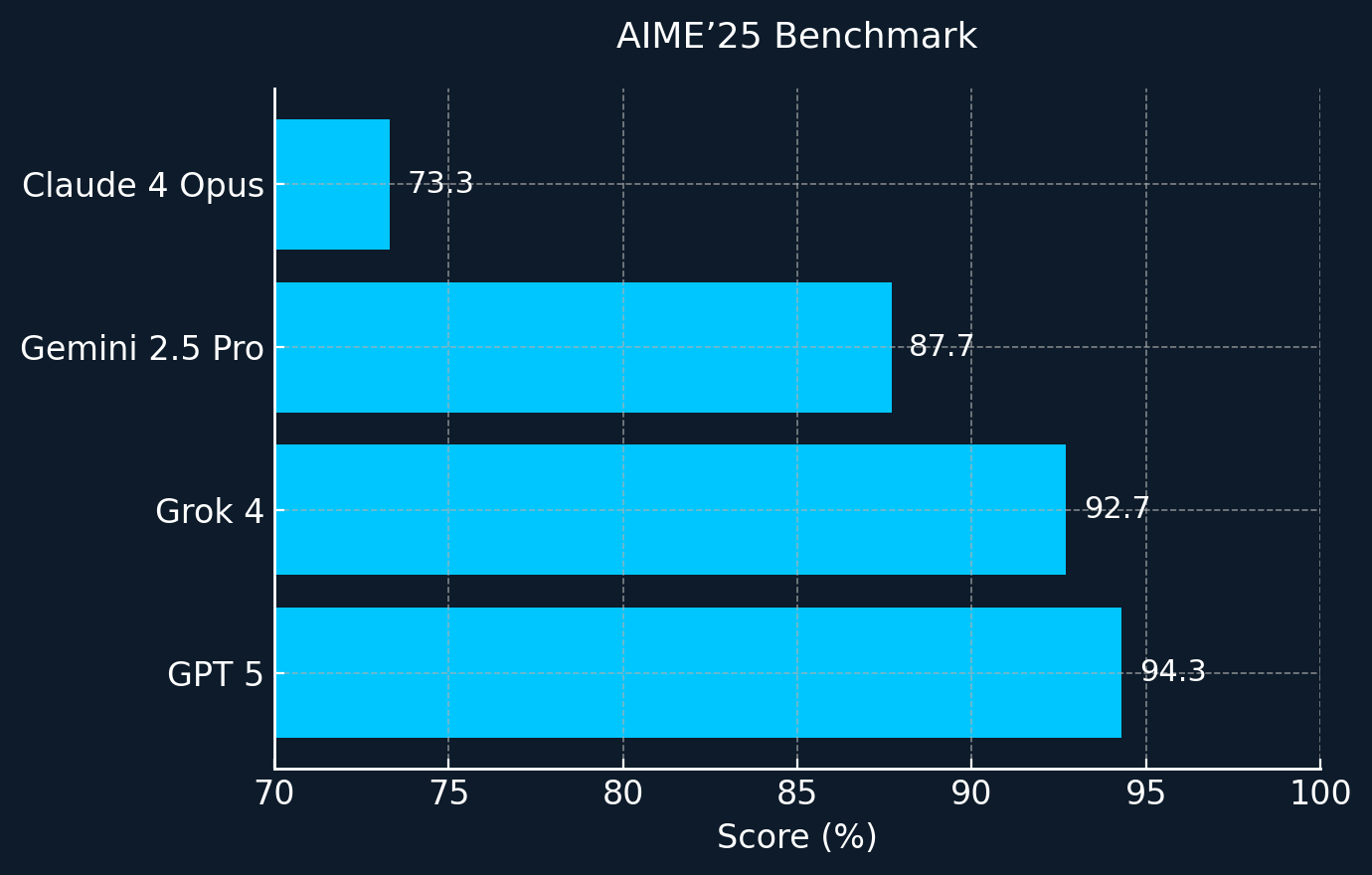
On other academic benchmarks such as GPQA and AIME’25, Grok outperformed most top competitors, with only the recent release of GPT-5 managing to edge it out by a narrow margin on AIME’25.
The ARC-AGI benchmark (Abstraction and Reasoning Corpus) is a test designed to measure the adaptive intelligence of AI systems. Unlike traditional benchmarks with large datasets, ARC-AGI presents tasks with only a few examples, requiring the model to infer the underlying pattern—a type of reasoning that comes naturally to humans but has historically been extremely challenging for AI.
In 2024, the benchmark’s creator released ARC-AGI 2, a harder version where most leading models struggled to even reach 10% accuracy. However, Grok 4 achieved 16%, setting a new milestone and demonstrating how modern reasoning models are beginning to close the gap with human-like problem-solving.
On August 28, 2025, xAI launched grok-code-fast-1, an agentic model specialized for development tasks:
This makes it a strong candidate for autonomous coding agents where cost and iteration speed matter more than generalist versatility.
You can access Grok 4 now in three different ways: the X app, the grok.com platform and the xAI API.
If you want even more power, the SuperGrok Heavy plan ($300/month) unlocks Grok 4 Heavy inside X as well.
Pros
Cons
Who is Grok 4 for?
Researchers, engineers, and professionals who need deep reasoning plus live information and automation.
What does Grok 4 Heavy add?
Multi-agent reasoning that improves accuracy on the hardest problems, with more latency and cost.
Is it enterprise-ready?
Improved but still requires guardrails, logging, and review for sensitive deployments.
How does it compare to GPT/Claude/Gemini?
Grok 4 leads in reasoning + tool use; GPT shines in ecosystem polish, Claude in safety, Gemini in long-context scale.
Grok 4 is a step-change: not just “bigger pre-training,” but better post-training reasoning through RLVW. With long context, integrated tools, and a multi-agent option, it’s one of the strongest models for complex, high-stakes problem solving today.
If you want to explore how Grok 4 could fit into your workflows, from research automation to agent-driven coding, reach out via the contact form. We’ll prepare a custom pilot plan—including objectives, prompts, guardrails, metrics, and cost estimates—so you can start measuring value within days.

A deep dive into building a white-label SaaS health platform with AI-powered lab analysis, tiered model routing, and per-clinic customization — from architecture decisions to production deployment.

Learn how Agentic AI in healthcare transforms care delivery with AI agents, automation, decision support, patient engagement, risks, compliance, and adoption strategy.


